



继本年4月推出Llama 3之后,Meta于7月24日认真发布了其功能更强劲的AI大模子Llama 3.1。Llama 3.1涵盖多个不同规模及功能的全新模子【FSET-432】夜勤中に居眠りしている看護師をレズ夜這い,其中包括当今可取得的、最大的洞开基础模子—— Llama 3.1 405B(4050亿参数)。Meta示意,算作当今最优秀和最大的开源基础模子(foundation models,FMs)之一, Llama 3.1 405B为生成式AI智商开拓了新圭臬。它相配适用于合成数据生成和模子蒸馏,这能在后续检会中普及较小尺寸Llama模子的性能。同期Llama 3.1 405B还在通用常识、数学、器具使用和多言语翻译方面有出色的推崇。
收获于大幅加多的检会数据和规模,统共新的Llama 3.1模子比较之前的版块王人有显豁纠正。这些模子撑抓128K的坎坷文长度,相较于Llama3加多了12万个标志(Token),模子容量是上一版块的16倍,并普及了在以下八种言语对话场景中的推理智商,即英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
Llama 3.1模子还增强对言语隐蒙眬别的分解智商,即能更好地分解坎坷文,并能更灵验地处理复杂问题。该模子还不错从长篇文本中取得更多信息,以作念出更贤人的决策,并诈骗更丰富的坎坷文数据生成愈加良好和凝练的恢复。
就在Llama 3.1发布确今日,英特尔就晓谕公司横跨数据中心、角落以及客户端AI居品已面向Meta最新推出的大言语模子(LLM)Llama 3.1进行了优化,并公布了一系列性能数据。英特尔示意,当今其丰富的AI居品组合已撑抓上述最新模子,并通过洞开生态系统软件完毕了针对性优化,涵盖PyTorch及英特尔PyTorch蔓延包(Intel Extension for PyTorch)、DeepSpeed、Hugging Face Optimum库和vLLM等。此外,企业AI洞开平台(OPEA)亦为这些模子提供撑抓。算作由LFAI & Data基金会发起的全新洞开平台阵势,OPEA旨在团聚生态之力,鼓舞立异,构建洞开、多供应商的、强劲且可组合的生成式AI措置决策。
凭据英特尔的官方数据,包括英特尔至强处理器、搭载英特尔酷睿Ultra处理器和英特尔锐炫显卡的AI PC居品王人完毕了对Llama 3.1的优化撑抓。
最初是英特尔至强处理器。算作通用盘算推算的基石,英特尔至强处理器为大众用户提供了强劲算力,当今第五代至强可蔓延处理器已通过各大云工作商面市,至强6能效核处理器也于本年6月份在中国认真发布。英特尔至强处理器在其每个中枢中均内置了英特尔高等矩阵蔓延(AMX)AI引擎,可将AI性能普及至新水平。凭据基准测试,在第五代英特尔至强平台上以1K token输入和128 token输出运转80亿参数的Llama 3.1模子,不错达到每秒176 token的吞吐量,同期保抓下一个token延长小于50毫秒。下图展示了运转撑抓128k长文本的80亿参数Llama 3.1模子时,下一个token延长可低于100毫秒。
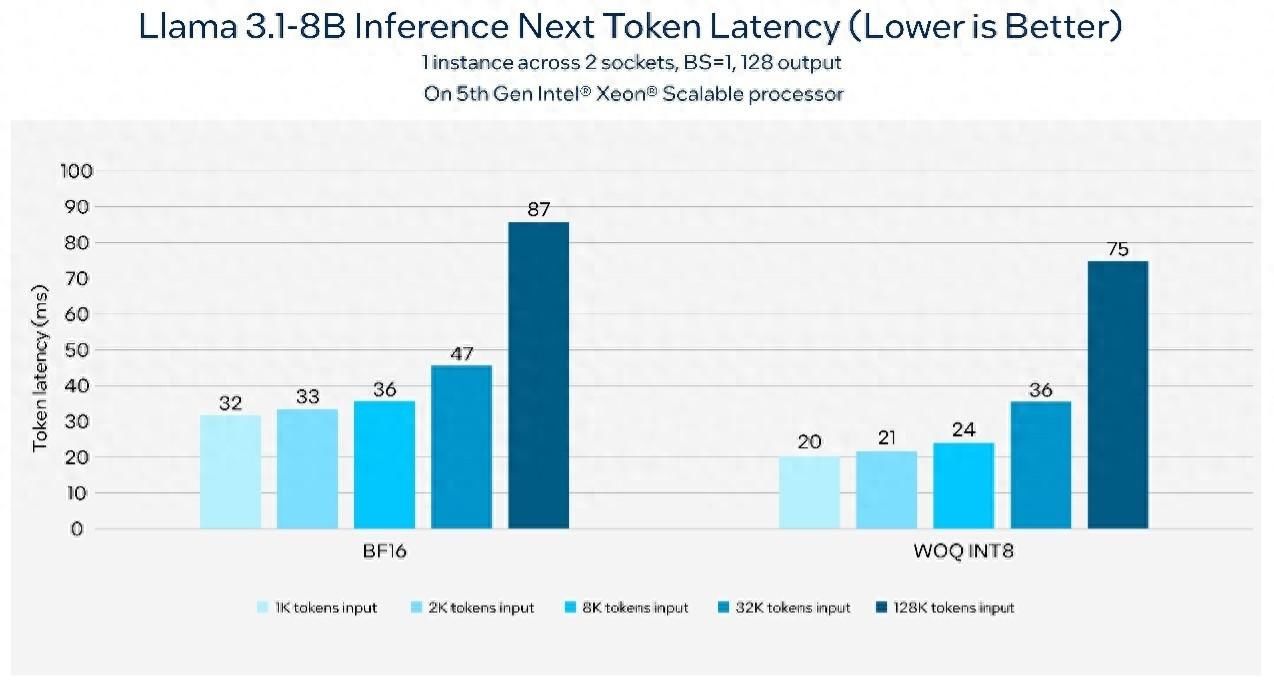
基于第五代英特尔至强可蔓延处理器的Llama 3.1推理延长
由英特尔酷睿Ultra处理器和英特尔锐炫显卡驱动的AI PC则能为客户端和角落提供超卓的开拓端AI推理智商。凭借诸如英特尔酷睿平台上的NPU,以及锐炫显卡上英特尔Xe Matrix Extensions加速等专用的AI硬件,在AI PC上进行轻量级微长入应用定制比以往愈加容易。关于土产货研发,PyTorch及英特尔PyTorch蔓延包等洞开生态系统框架可匡助加速。而关于应用部署,用户则可使用英特尔OpenVINO器具包在AI PC上进行高效的模子部署和推理。AI责任负载可无缝部署于CPU、GPU以及NPU上,同期完毕性能优化。

在配备内置英特尔锐炫显卡的英特尔酷睿Ultra 7 165H AI PC上,Llama 3.1推理的下一个token延长
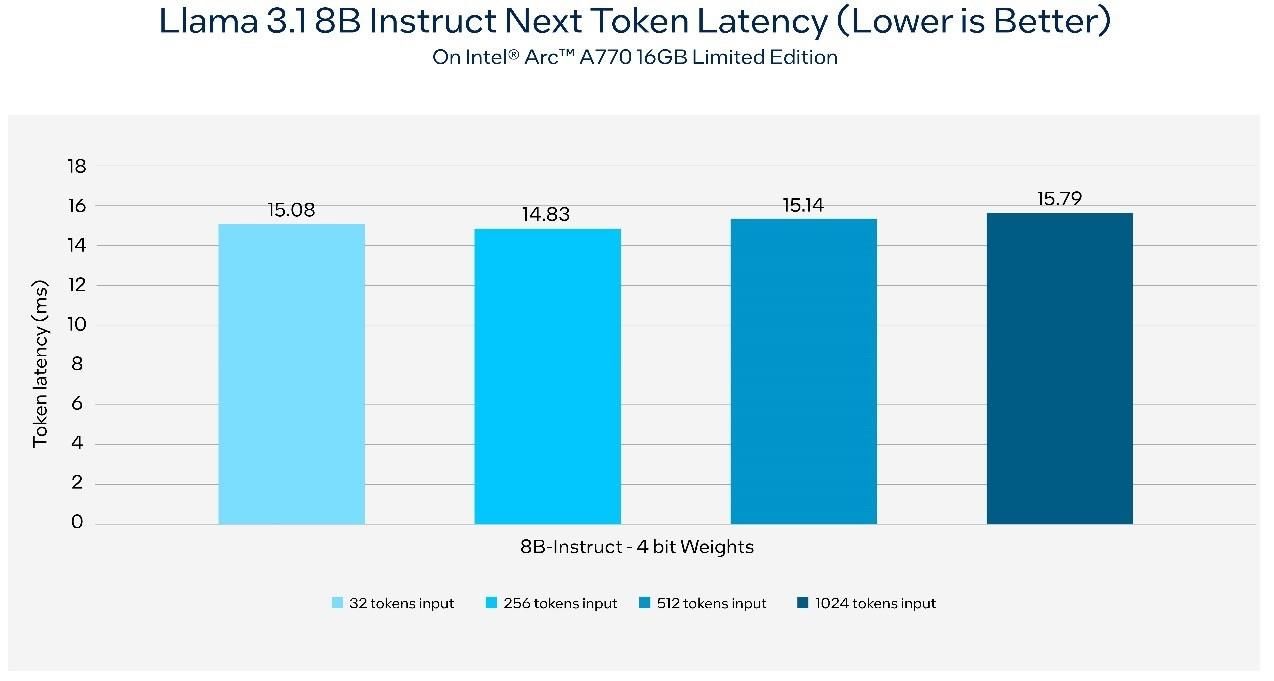
在使用英特尔锐炫A770 16GB限量版显卡的AI PC上,Llama 3.1推理的下一个token延长
现如今,诸多企业王人领有规模雄伟的历史数据,这些数据每每被视作企业的专有财产,因此无法被大模子平直拜访,对这些企业而言,部署生成式AI措置决策会带来诸如老本、规模、准确性、开发需求、秘密和可靠性等方面的挑战。算作一种重要的生成式AI责任负载,RAG不错让企业安全地诈骗专非凡据,增强AI产出恶果的实时性与可靠性。
为了进一步加速RAG时刻部署,鼓舞生成式AI措置决策快速落地,英特尔与行业配联合伴共同创建了开源、可互操作的措置决策。基于企业AI洞开平台(OPEA),该决策是一种以行业需求为导向、开箱即用,且可立即投产的RAG措置决策。该生成式AI一站式措置决策在助力企业方便地部署数据中心RAG的同期,具备高度的机动性和可定制性,并集成了多个OEM系统及行业配联合伴的居品组件。
算作OPEA的发起成员之一,英特尔正匡助引颈行业为企业AI打造洞开的生态系统,同期,OPEA亦助力Llama 3.1模子完毕性能优化。
基于可组合且可确立的多方配合组件,OPEA为企业提供开源、圭臬化、模块化以及异构的RAG活水线(pipeline)。这次测试中,微工作部署于OPEA蓝图的每一支细分规模中,包括注意(Guardrail)、镶嵌(Embedding)、大模子、数据索求及检索。端到端RAG活水线通过Llama 3.1进行大模子的推理及注意,使用BAAI/bge-base-en-v1.5模子进行镶嵌,基于Redis向量数据库,并通过Kubernetes(K8s)系统进行编排。
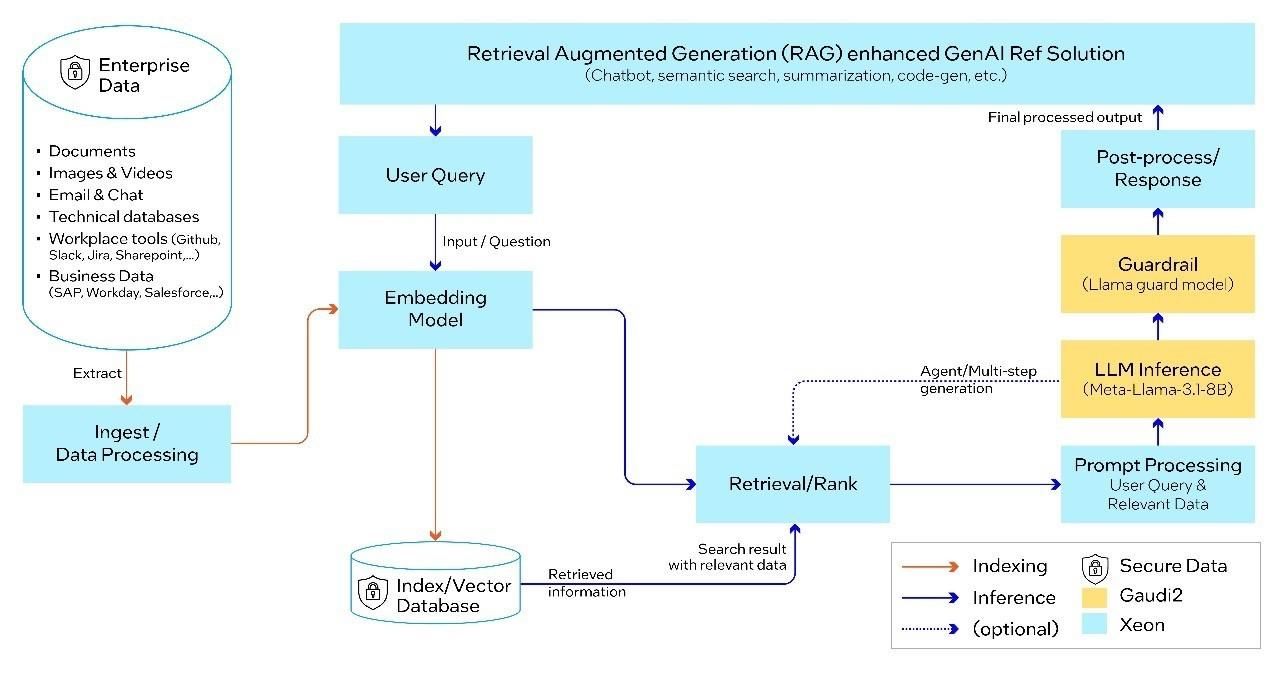
基于Llama 3.1的端到端RAG活水线,由英特尔Gaudi 2加速器和至强处理器提供撑抓
163男女性爱当今,英特尔AI PC及数据中心AI居品组合和措置决策已面向全新Llama 3.1模子完毕优化,OPEA亦在基于英特尔至强等居品上全面启用。将来,英特尔将抓续进入软件优化,撑抓更多全新的模子与用例。
(8868500)【FSET-432】夜勤中に居眠りしている看護師をレズ夜這い